

 Google Scholar
Google Scholar

Prompt Refinement or Fine-tuning? Best Practices for using LLMs in Computational Social Science Tasks
What ChatGPT says about the paper — will be edited.
The Versatility of LLMs in Social Science
As large language models (LLMs) become more embedded in the field of computational social science, many of us are left wondering: how do we get the best out of these models for tasks like text classification? Should we rely on fine-tuning, prompt refinement, or something else? This paper dives into that question, providing a well-rounded view of LLMs’ capabilities on 23 different social knowledge tasks from the SOCKET benchmark.
By evaluating methods like zero-shot prompting, AI-enhanced prompting, fine-tuning, and instruction-tuning, the authors offer insights that can guide us in making informed choices when using LLMs for social science tasks.
Key Takeaways from the Paper
This paper is all about determining the best practices for using LLMs in our field, whether we’re dealing with humor detection, offensive content classification, or sentiment analysis. The authors highlight three primary recommendations:
-
Model Choice Matters
Larger vocabularies and more comprehensive pre-training datasets improve the model’s performance. For example, Llama-3 significantly outperforms Llama-2 on several tasks due to its richer pre-training data. -
Prompting Strategy
Simple zero-shot prompts don’t cut it for complex tasks. We should aim to use enhanced prompting strategies, such as using AI-generated task-specific knowledge or even Retrieval-Augmented Generation (RAG), which combines search-based data with model-generated text. These methods give the model more context and improve accuracy across different tasks. -
Fine-tuning Is Still Key
When we have enough task-specific data, fine-tuning clearly outperforms prompting alone. This doesn’t mean we need vast datasets—techniques like QLoRA (Quantized Low-Rank Adaptation) allow us to fine-tune efficiently, even with limited resources.
In the table below, you can see our results on the SOCKET benchmark
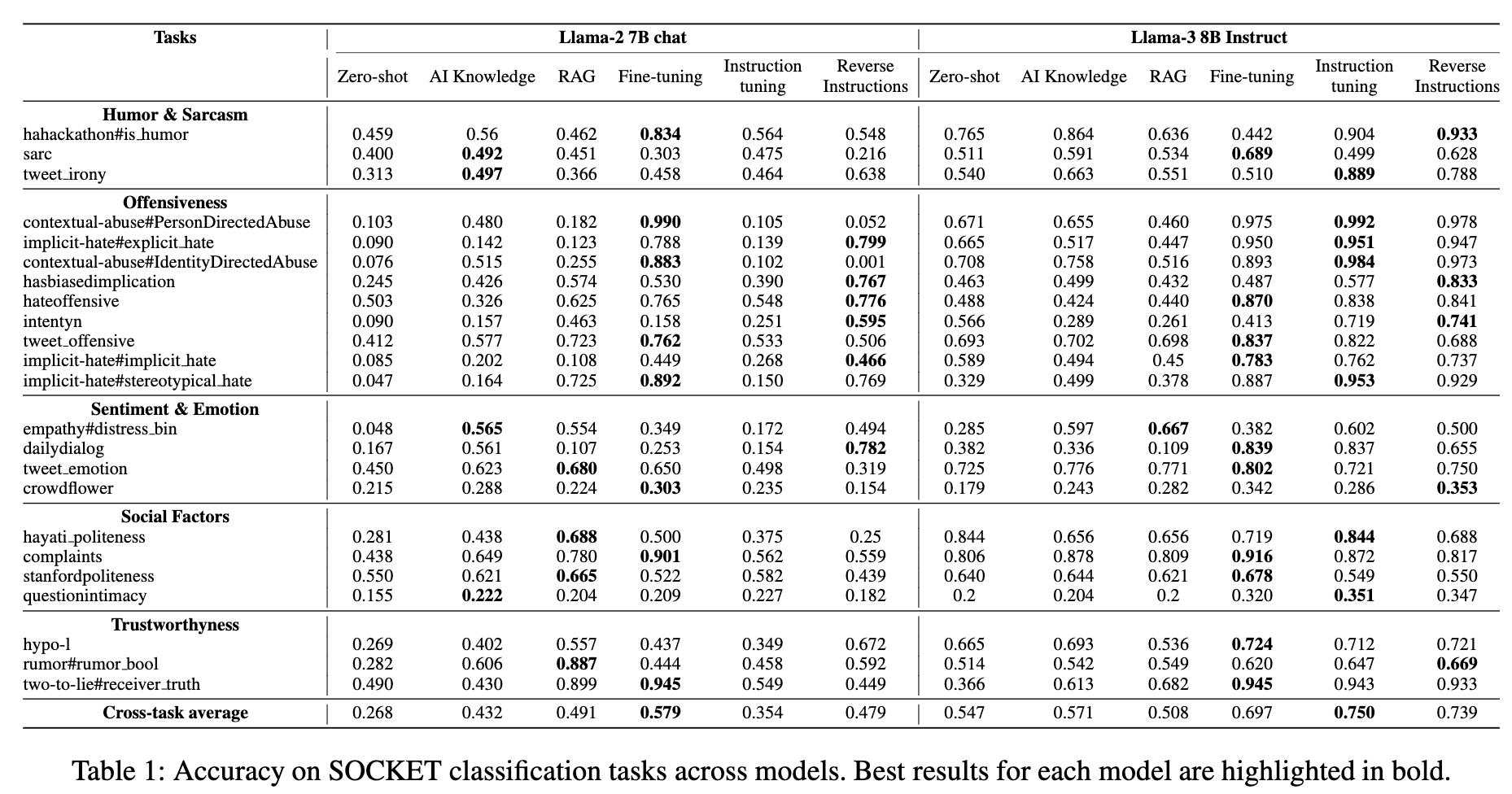
What Worked and What Didn’t
The paper’s experiments compared six state-of-the-art methods across two versions of Llama (Llama-2 and Llama-3) using 23 datasets from the SOCKET benchmark, which covers five key areas: humor & sarcasm, offensiveness, sentiment & emotion, trustworthiness, and social factors.
Prompt Refinement vs. Zero-shot
Enhanced AI knowledge prompts consistently outperformed simple zero-shot methods. This suggests that adding task-specific knowledge into the prompt—even if generated by the AI itself—makes a notable difference. For instance, when dealing with humor detection or offensive language, using more detailed prompts based on contextual knowledge improved accuracy.
Fine-tuning with QLoRA
Fine-tuning, especially with methods like QLoRA, boosted performance significantly. On average, fine-tuning added a 13-15% increase in accuracy compared to baseline prompting methods. However, the resource costs can be high, so it’s important to weigh the benefits versus the computational demands. That said, QLoRA provides a solid middle ground, offering efficient fine-tuning for those with limited resources.
Instruction-Tuning: A Mixed Bag
Instruction-tuning had mixed results, performing better on Llama-3 than Llama-2. While this method allows the model to generalize across tasks, the authors found that Llama-2 struggled with the additional complexity introduced by instruction-tuning, often leading to performance drops.
Practical Implications of Our Work
For us working in computational social science, this paper gives some clear direction on how to approach our LLM-based projects. If you’re dealing with a task that has little data, smart prompting strategies (like using AI-generated task knowledge) can improve your results without the need for fine-tuning. On the other hand, if your task is complex or you have a good amount of task-specific data, fine-tuning is the way to go.
A Roadmap for LLM Usage in Social Science
This paper attempts to lay out the pros and cons of different LLM strategies, giving us actionable advice for how to approach different types of tasks. We need to continue balancing the trade-offs between prompt refinement and fine-tuning, and being strategic about when to use each.
Want to know more or see how we implemented the experiments? Check out our Github repo.